
The Read Model
Saving Aggregate state is fun and all, but we can’t ONLY do that. There’s that one important piece of our Use Case(s) that we are forgetting… Nick actually using the app. Nick needs to make decisions based on the state of the Aggregates in the system. Remember Brandolini’s “Picture that Explains Everything”…
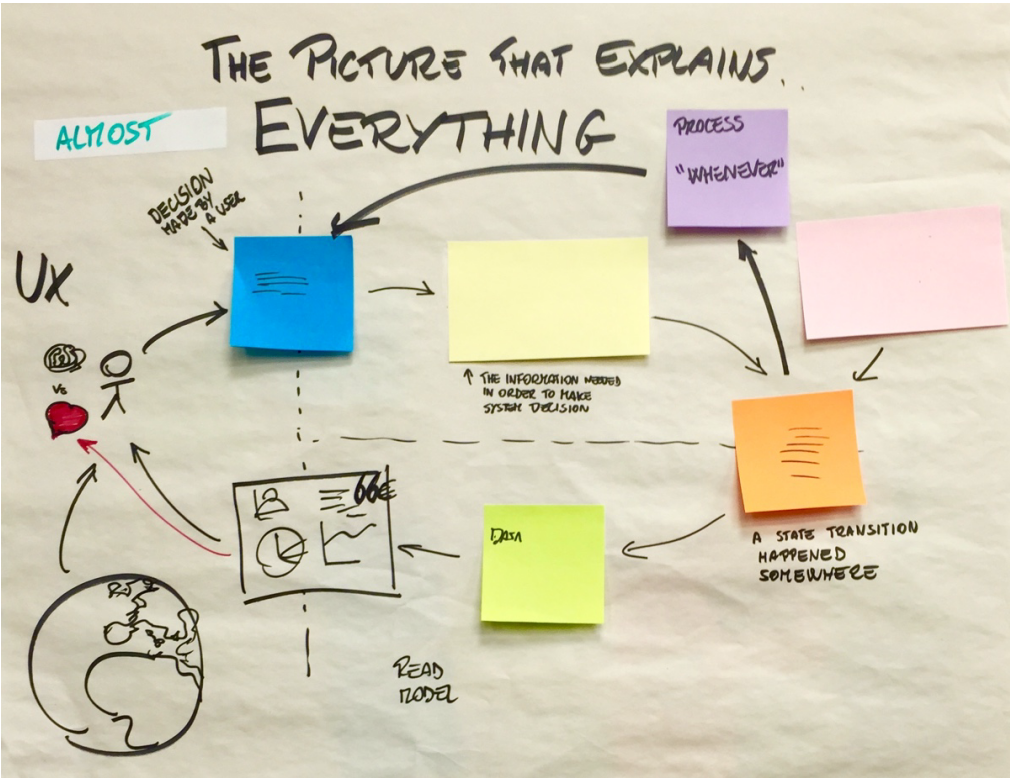
Brandolini mentions in his talk The Precision Blade that the goal of EventStorming is to model a flow of decisions. In order for Nick and his Customers to make decisions, they’re going to be looking at data in different ways. They’re going to be looking at Aggregates like RoastSchedule with a bias for making a decision for their own benefit, not simply any old representation of Aggregate data.
This is where the CQRS Read Model comes into play. Since we have Event Sourced our RoastSchedule Aggregate, how are we going to show Nick his newly created Roast Schedule?
Let’s take inventory of what we’ve already created…
- Commands: they demand change in Aggregate State, mostly initiated by the User through a User Interface. They can fail and be denied.
- Aggregate base class: that has the means to manage state by processing Commands into Events and is able to figure out its state from a series of Events.
- Events: they signify that our Aggregate state has been modified and are used to persist the Aggregate’s state.
- Event Sourced Repository: which, for now, is built on an in-memory Event Store that persists Events to it.
We can look at these components as our CQRS Write Model: Commands -> Aggregate -> Events -> Event Sourced Repository.
With our Read Model (a.k.a. Query Model) we decouple the reading of data from the Commands -> Aggregate writing of data. The Read Model isn’t responsible for changing state. This decoupling is what allows the possibility of Polyglot Data (Greg Young). Polyglot Data is our ticket to being able to cater our Read Model for the decisions that the User needs to make.
Do we need the CEO to hook a pivot table up to a SQL Server SSAS Cube so they can slice and dice bookings for the last two years? Do we have deep graphs of objects that would be really inefficient to store in SQL, but would be perfect for neo4j? Are we doing several joins just to get to the point where we can show a record on a web page? Decoupling our Write Side and Domain Model from our Read Side allows us to do these things, and is a good selling point for employing CQRS in some parts of our architecture.
For the tactical implementation of our Read Model, there are a couple more components that we’ll need to talk about, including Projections and the Bus. So stay tuned!
I will be releasing most of this content only to subscribers. Make sure you sign up by clicking the big red button!
Related Posts:
- An Executable Specification
- Testing an Event Sourced Aggregate Root
- Aggregate Event Persistence
- Event Store
- Command Handlers
- Implementing an Event Sourced Aggregate
- Design Level Continued
- Complexity and Cost
- Design Level EventStorming
- People and Commands
- Hotspots
- Domain Discoveries
- Big Picture EventStorming
- The Domain - First Pop Coffee Company
- More Efficient Domain Modeling with EventStorming
- Where do you find resources for learning DDD, CQRS, Event Sourcing, and EventStorming?
- Has the code devolved into a big ball of mud?… What can you do about it?
- A Better Way to Project Domain Entities into DTOs
- Exposing IQueryable in a CQRS Query Stack
- A Pattern to Decouple your Aggregates from their Clients
- Erlang-style Supervisors in C# with Akka.NET and the Actor Model